データベースの世界で、インデックス(索引)とはテーブルに格納されているデータを
高速に取り出す為の仕組みを意味します。
インデックスを適切に使用することによってSQL文の応答時間が劇的に改善
される可能性があります。
インデックスにはB-Treeインデックスをはじめ、ビットマップインデックス、
関数インデックスなどの種類がありますが、ここでは最も一般的に使われ、かつ
ほとんどのDBMSでサポートされているB-Treeインデックスについて解説します。
※ CREATE INDEX文でオプションを指定しない場合は通常B-Treeインデックスが
作成されます。
■ B-Treeインデックスのしくみ
B-Tree(Balanced Tree)インデックスは次のようなツリー状の構造になっています。
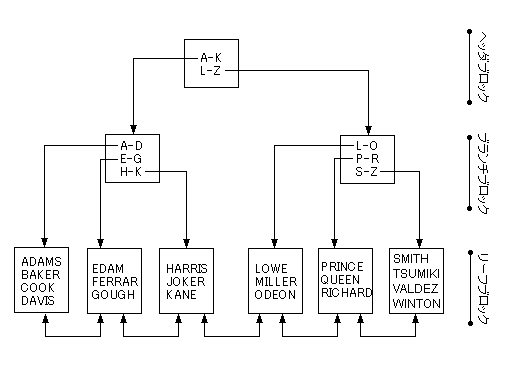
ツリーの先頭はヘッダブロックと呼ばれています。ヘッダブロックでは、キー値の
範囲と下層のブロックへのポインタを管理していて、キーの値が指定された場合に、
次にどのブロックを読めばいいかが分かるようになっています。
ブランチブロックはキー値を更に細かく分割して管理しています。キー値が多い
場合はブランチブロックが複数連なります。
リーフブロックは最下層のブロックでキー値とテーブルの行の物理的な位置を
管理しています。又、リーフブロックには前後のリーフブロックへのポインタが
含まれており、<、>、BETWEENなどの範囲検索がスムーズに行われます。
図のインデックスを使って「TSUMIKI」を検索する場合、次のような経路で実際の行への
アクセスが行われます。
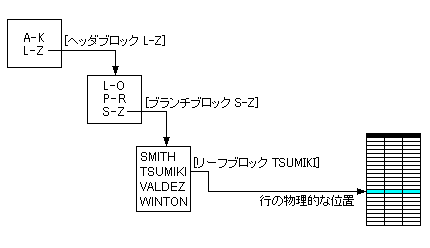
■ B-Treeインデックスの特徴
B-Treeインデックスはその構造から次のような特徴を持っています。
・どのようなキー値でも、同一の速度が期待できる。
(これは全てのリーフブロックが同じ深さになっているためです。)
・大量のデータでも良いパフォーマンスが期待できる。
(これは大量のデータを格納した場合でも、インデックスの深さが4ブロック以内に
収まることが多いためです。又、ヘッダやブランチ部分はメモリ上にロードされて
いることが多く、実際には1,2ブロックの読み込みで済むことから推測されます。)
・一致検索(=による検索)だけでなく、範囲検索(<,>,BETWEENによる検索)を行うことが
できる。(これはリーフブロックに前後のリーフブロックへのポインタが
含まれており、前後のデータを連続して処理することが出来るためです。)
・ソート処理を高速に行うことが出来る。
(これはインデックス内の各データが既にソートされて格納されているためです。)
■ B-Treeインデックス使用時のオーバーヘッド
B-Treeインデックスは柔軟で効率的な検索をサポートしてくれます。
しかしその一方で、データを更新するときには、その構造を維持するために
オーバーヘッドが発生します。
インデックスが複数設定されていると、更新処理に必要な時間が数倍になることも
あります。
インデックスを作成する場合には、更新系処理と検索系処理のバランスを考えながら
作業することが必要になります。
なお、比較的大きな表では更新系処理よりも検索系処理の方が負荷が高いため、
一般的にはインデックスを作成した方が、トータルパフォーマンスは向上する
可能性が高いようです。
また、当然ながらインデックスを作成するには、そのためのディスク容量が必要に
なります。個々のインデックスの容量は表に比べれば小さいものですが、ひとつの
表に複数のインデックスを作成した場合には、表とインデックスを合計した容量が
元の表の2倍以上になることもあります。
■ B-Treeインデックスが有効に動作するデータ取得量
B-Treeインデックスが有効に動作するのは、取得するデータの量が表全体の
5%〜15%以下の場合です。一概には言えませんが、それ以上のデータを取得する
場合や、検索する表の容量が小さい場合は、インデックスを使用しないで全表走査
(表のすべての行を読み込んでWHERE条件を判定)した方が高速になります。
■ B-Treeインデックスの選択性
重複しているキー値が少なければ選択性が高く、インデックスは有効に働きます。
たとえば誕生日を表す列は選択性が優れていますが、性別を表す列は選択性は
悪いでしょう。
選択性の優れているインデックスは特定のキー値で対象となるデータを
絞り込めるので効率的に機能します。
ユニークインデックスやプライマリキー(NULLを許可しないユニークインデックス)は
最も選択性の高いインデックスです。たとえ膨大な量のデータが存在する表でも、
プライマリキーを使用した一意検索であれば1秒以下の応答が期待できます。
なお、OracleなどのDBMSでは選択性の悪い列に対して効果を発揮するビットマップ
インデックスというインデックスがサポートされています。
■ 結合インデックス
結合インデックスとは、複数の列で構成されるインデックスのことです。
WHERE句でよく複数の列が指定される場合は、それらの列に対してインデックスを
作成するとより効果的な検索が可能になります。
たとえば、
SELECT
first_name,second_name
FROM
tsumiki_mst
WHERE
first_name='値' AND
second_name='値'
のようなSQL文を実行する場合は、
次のようなインデックスを作成すると検索が高速になります。
CREATE INDEX tsumiki_mst_name_idx
ON tsumiki_mst(first_name,second_name)
このインデックスはfirst_nameを単独で指定したときにも機能するので、
first_nameのインデックスの代わりに使うこともできます。
しかし、second_nameを単独で指定した場合には機能しません。
これは、結合インデックスは最初の列から連続して列が指定されている場合にのみ
機能するという制限があるからです。
たとえば、A,B,Cの順序でインデックスが指定されている場合、有効/無効は次の
ようになります。