SAINT2004, Tokyo Japan, January 26-30, 2004
Workshop 4: Metadata Applications on the Broadband Network
by Atsushi Yamada (ASTEM/RI Kyoto)
Fumio Adachi (National Museum of Japanese History)
Yushi Komachi (Panasonic Communications)
Ray Atarashi (Internet Initiative Japan)
For supporting a variety of museums and satisfying a variety of user requirements to access the museums information, an integrated access scheme is discussed and proposed. The integration is based on a proposed layered framework. Some experiments on a prototype system of museum information access are shown for layer 1 and layer 2 of the framework.
A number of museums today provide their museum data on their network services. From a user's point of view, those electronic museum services have the following problems:
In order to solve those problems, there could be required such an integration mechanism that user can access all the museum data without considering the actual locations of museums, and syntaxes/semantics of meta-data and content-data of museums.
Some other integration trials (e.g., development of an integrated format of museum data) have been taken, for example, in ICOM-CIDOC[1] and Forum of the Information System on Cultural Properties and Art in Japan[2].
There are a variety of museums, which have different scopes, subjects, scales, backgrounds and purposes from each other. It leads to their specific meta-data and content-data formats and results in their specific exhibitions. Besides, there are a variety of user's/visitor's interests and expertise.
For supporting a variety of museums and satisfying a variety of user requirements to access the museums information, we have to consider an integration of semantics of museum data as well as syntaxes of the data.
NOTE: Digitizing the objects of museum is important for discussing museum information but it is outside the scope of this article. Subject data management[3] within a museum is also outside the scope. This article is based on our preliminary works published in [4], [5] and [6].
In a museum some subjects are called collections. However they are called historical materials in other museums. A naming rule of subjects/collections/materials within a museum may be different from other museums. A visitor to a museum may have no exact naming of a subject/collection/material.
As far as an old book in a museum is concerned, some visitors are interested in its language aspect and other visitors may interest in its printing layout. The aspect for a subject of a museum is not always identical to the aspect of a visitor.
An exhibition of a museum has to focus on the variety of visitor's interests. An exhibition of a museum is sometimes required to be customized in accordance with visitor's interests, e.g., for children, students, experts, etc.
Technical requirements for an integration of syntaxes and semantics of museum data lead to the layered framework:
The layer 1 deals with a sharing and conversion of information structures for museum data. The layer 2, a sharing and conversion of vocabularies within described information contents for museum data. The layer 3 supports a sharing and linking of museum information for navigating various knowledge about objects.
Museum data are described with their structure, e.g., XML-DTD, XML-Schema, etc. The structured data can be shared between museums by some structure conversion, even if the museums have their own structured data different with each other. The structure conversion can be carried out with such a mapping specification between structures. A mapping specification is described by a description language, e.g., XSLT[7].
Assume museums A and B, which have different structures of their database. When slot x of museum A database schema can be mapped with slot y of museum B database schema, data sharing between A and B can be executed by the conversion in accordance with the mapping specification x-y.
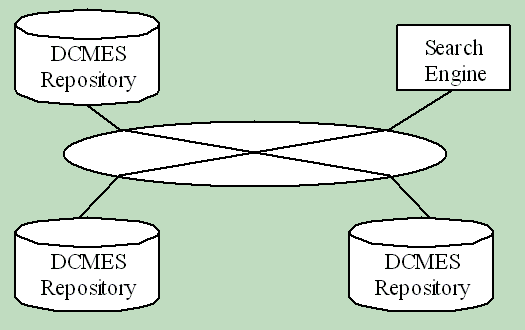
A star mapping with a centered common structure can minimize the number of mapping specification.
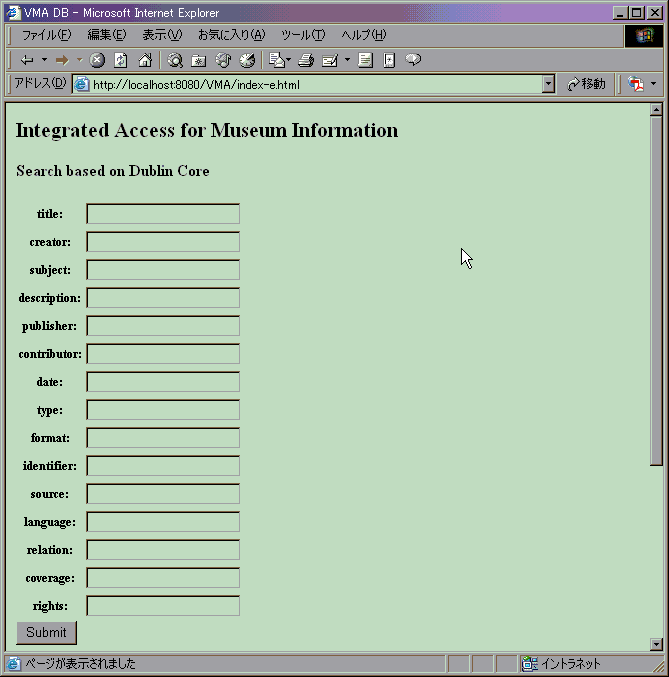
It is desirable for the centered common structure to have sufficient expression capability. In our prototype system, Dublin Core Metadata Element Set V1.1 (DCMES)[9] developed by Dublin Core Metadata Initiative (DCMI), which is one of the commonly used metadata structure, is used as the centered common structure for the information structure mapping. The slots described in DCMES are shown in Table.1.
| 1. | title |
| 2. | creator |
| 3. | subject |
| 4. | description |
| 5. | publisher |
| 6. | contributor |
| 7. | date |
| 8. | type |
| 9. | format |
| 10. | identifier |
| 11. | source |
| 12. | language |
| 13. | relation |
| 14. | coverage |
| 15. | rights |
The basic design of the prototype system is as follows:
In the first step, in-house data of a museum should be converted to DCMES instances, which will be stored in the repositories. We used a general XML structure transformation method in the following steps:
There are various ways for the implementation of the repositories. It may depend on the specification of the communication between the search engine and the repositories. As the large amount of the DCMES instances should be stored in a repository, it is reasonable to use a database system. In our prototype system, the repository is implemented on Xindice[10], which is a native XML database, and the communication is based on XML:DB API[11].
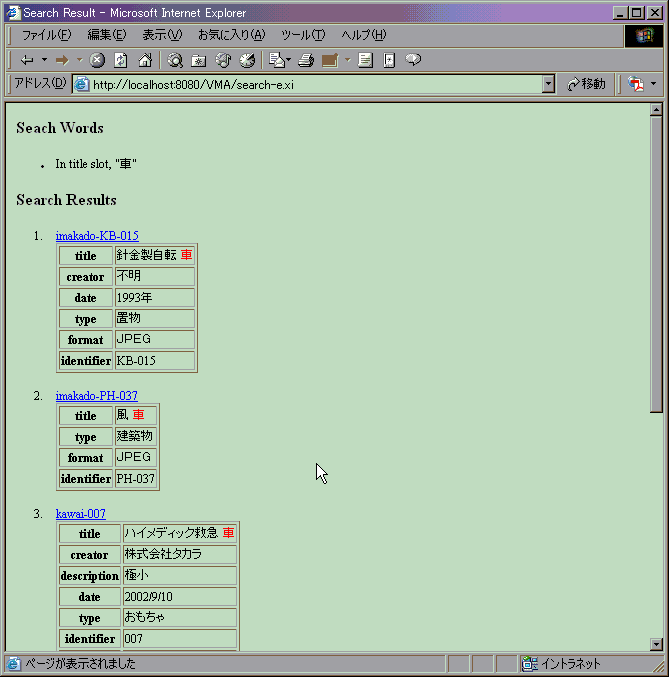
The search engine is a web-based system which accepts user's search request, sends query to the repositories, receives query result from the repositories, and constructs and shows result web page to the user. We build the prototype system using BayServer[12] and Xi[13]. The input page for the user's request is shown in Figure.2, and an example of the search result is shown in Figure.3.
Even in the converted and shared data structures, there are the following cases:
The case 1 results in an unretrievable content. In the case 2 retrieved contents include an error. Those cases require a sharing and conversion of vocabularies describing information contents.
Vocabulary sharing can be realized by the following schemes
The scheme 1 is effective within a comparatively small community or a specific group. The scheme cannot be applied to open environment, since it is difficult to define a versatile set of vocabularies. Here we have to take the scheme 2 for contents for a variety of museum.
The same concept may be expressed with different words. In Japanese, you may use Kanji or Kana for describing the same word. The content word level mapping using synonym or alias dictionary will resolve such surface word difference.
Users may want to retrieve instances classified into some groups. The classificatory criterion reflects the interest of the classifier, and may differ among museums. In this case, finding the corresponding class in different classifications becomes the problem. Ontology describes class-subclass-instance relationships. Subclasses are divisions of the parent class. For example, there is a class X and classificatory criteria A and B. If the criterion A is applied to X at first, it is divided into subclasses X-A1 and X-A2. Then X-A1 is divided into subclasses X-A1-B1 and X-A1-B2, and X-A2 is divided into X-A2-B1 and X-A2-B2 using the criterion B. In different case, X is divided into subclasses X-B1 and X-B2 using the criterion B at first. In these different classifications, X-B1 corresponds to X-A1-B1 and X-A2-B1. Finding the equivalent classes in different ontologies, which have the same feature attribute value is the key issue.
In the layer 3, relationships between objects are described. Relationship and object information should be described distinctively. An example of the relationship is a hyperlink to a museum object from a report or book dealing with the object.
The knowledge of curators or experts is represented as the relationships. They can describe a scenario to navigate visitors to a museum. A scenario may be created by a teacher as a school text. There could be a number of scenarios for a number of specific scopes and purposes.
Linking can easily be described outside museum information by using XLink [8]. Scenario description should be for further study.
A layered framework for supporting a variety of museums and satisfying a variety of user requirements to access the museum information is proposed. The framework consists of three layers; (1) information structures, (2) information contents, and (3) information navigation. An evaluation on a prototype shows that sharing and conversion of the 1st layer can be realized easily using XML and XSLT description and clarified the technical requirements for the 2nd layer.
Ontology description has a possibility to carry out mapping of classification between different museums, which is the main issue for sharing and conversion of the 2nd layer. Sharing and linking of the 3rd layer is a further study.
[1] The International Committee for Documentation of the International Council of Museums (ICOM-CIDOC), http://www.willpowerinfo.myby.co.uk/cidoc/
[2] Forum of the Information System on Cultural Properties and Art in Japan, http://www.tnm.go.jp/bnca/doc/Intro.en.html
[3] CIMI Consortium Museum Intelligence, http://www.cimi.org/
[4] A. Yamada, et al, Framework for integrated access to museum information, IIEEJ Annual Conference, 2002-06-21 (in Japanese)
[5] A. Yamada, et al, Conversion of museum information structure and its prototyping, 10th VMA Conference, IIEEJ, 2003-01-17 (in Japanese)
[6] A. Yamada, et al, Mapping and conversion of contents for integrated access to museum information, IIEEJ Annual Conference, 2003-06-19 (in Japanese)
[7] XSL Transformations (XSLT) Version 1.0, http://www.w3.org/TR/xslt
[8] XML Linking Language (XLink) Version 1.0, http://www.w3.org/TR/xlink/
[9] Dublin Core Metadata Element Set, http://www.dublincore.org/usage/terms/dc/current-elements/
[10] Xindice, http://xml.apache.org/xindice/
[11] XML:DB API, http://www.xmldb.org/xapi/
[12] BayServer, http://www.baykit.org/bserv/
[13] Xi, http://www.baykit.org/xi/