これは、PDF文書の文字データを、テキスト・ファイルとして出力する、簡単なツールです。
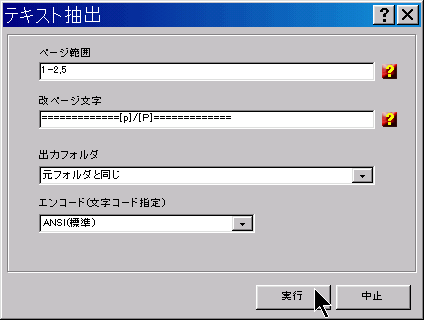
ページ範囲 の欄で、テキスト抽出するページを指定します。すべてから抽出する場合は、この欄は空白でかまいません。
改ページ文字 は、出力テキストファイルの改ページのしるしに使われる文字列です。
ページ番号を表示したい場合には、コントロール文字[p]を入れてください。総ページ数を挿入したい場合には、コントロール文字[P]を使います。
出力フォルダ の枠で、作成されたテキスト・ファイルを出力するフォルダーを指定します。
エンコード・オプションは、テキスト・ファイルをコード化するために使う「文字コード」を指定します。ANSI、UTF8、および UNICODE から選択してください。
コマンド・ライン・インタフェース:
| 機能名: | TextExtract |
| オプション: | [] は、任意のパラメータを意味します。 |
| [PageRange=] | - Define the document pages range from where to extract text. If not specified, extract from all pages. Se above image for rules. |
| [PageBreak=] | - Define the string used to signal page breaks. Insert [p] to write page number and [P] to write the total number of pages. |
| [Encoding=] | - Text output encoding. 0 - ANSI 1 - UTF8 2 - Unicode |
| [OutputPath=] | - Full path where to create the text files. If not specified, file source path is used instead |
| [-s] | - サイレント・モード。メッセージを表示せずに実行します。(ライセンス・ユーザのみ使えます) |
| FilesList | - 文字データを抽出する PDF のリスト。セミコロン ";" を使って、ファイル名を並べて下さい。パラメータの最後に書きます。 |
| 例: Rundll32 "c:\Program Files\PDF-ShellTools\PDFShellTools.dll",TextExtract "pagerange=1,3-5" encoding=0 "pagebreak=-- [p]/[P]--" "c:\somefolder\file1.pdf;c:\somefolder\file2.pdf" |
|