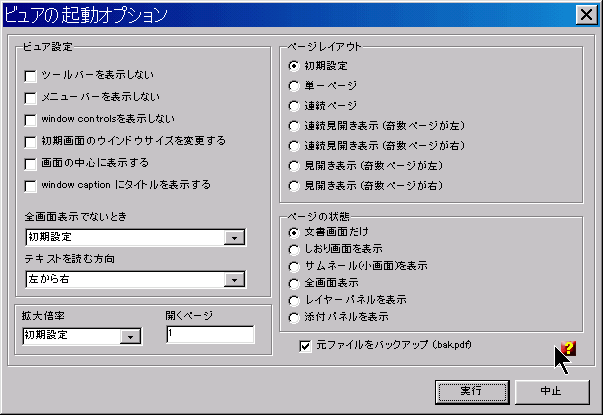
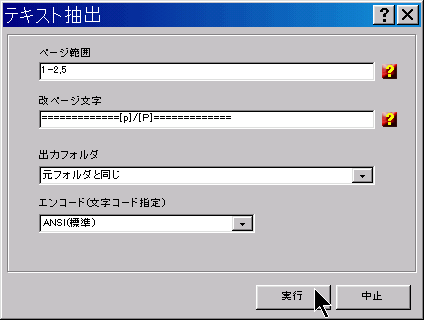
 PDF文書の文字データを、テキスト・ファイルとして出力する、ツールです。
PDF文書の文字データを、テキスト・ファイルとして出力する、ツールです。「ページ範囲」 の欄で、テキスト抽出するページを指定します。すべてから抽出する場合は、この欄は空白でかまいません。 「改ページ文字」 は、出力テキストファイルの改ページのしるしに使われる文字列です。 ページ番号を表示したい場合には、コントロール文字[p]を入れてください。 総ページ数を挿入したい場合には、コントロール文字[P]を使います。 「出力フォルダ」 の枠で、作成されたテキスト・ファイルを出力するフォルダーを指定します。 「エンコード(文字コード指定)」は、テキスト・ファイルをコード化するために使う「文字コード」を指定します。ANSI、UTF8、および UNICODE から選択してください。 |
|
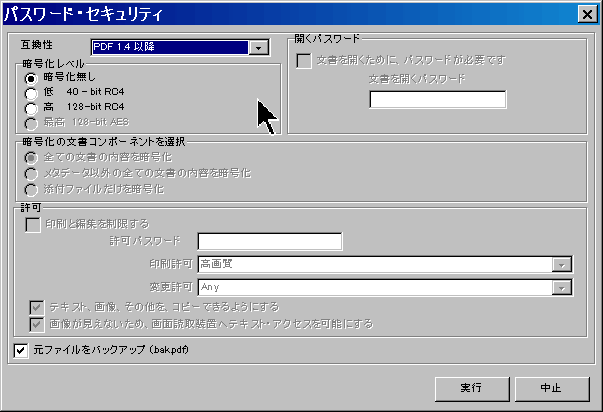
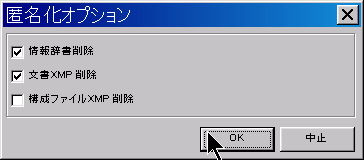
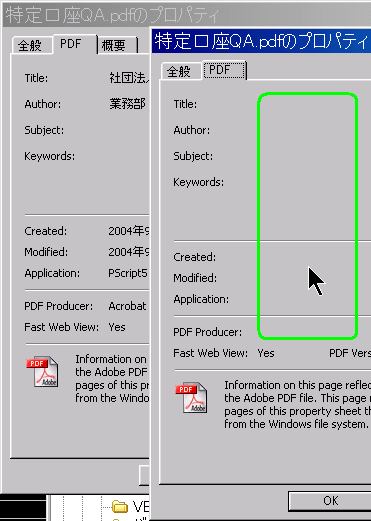
匿名化(情報秘匿):PDFファイルに書かれている情報を削除します。 「匿名化」を実行すると、PDFドキュメントが持っている全てのメタデータ(属性情報)を削除します。 どんなツールでPDFを作ったか、いつファイルが作られたかなどの情報を、取得できなくします。 情報辞書(Info Dictionary)と文書XMP(Document XMP)は同等で、それぞれ、標準と、Adobeあつらえの文書メタ情報項目が登録されています。PDFファイルで、その情報を登録するために、2つの異なった場所を使っているので、分けて表示されています。 情報辞書(Info Dictionary)は、PDF文書規格の初めから設定されていました。 XMP(Extensible Metadata Platform 拡張メタデータ基盤)は、Adobe Systems社が開発した、画像ファイルに関する、日付・タイトル・撮影条件などの情報(メタデータ)を記述する規格です。PDFを取り扱うツールが、古いバージョンの情報辞書(Info Dictionary)のファイル構造を考慮しなくても、ファイル・メタデータを走査できるようにするために、作られました。このタイプのメタデータ・オブジェクトは、ほとんど、どんなタイプの種類のファイルも、埋め込むことができるようになっています。 構成ファイルXMP(Components XMP)は、ビットマップ画像や、Vector画像など、PDFに添付できる要素のメタデータに対応しています。通常、その要素を作ったり加工したりするのに使われたツールから、情報を登録します。 右のサンプルのように、ファイルのプロパティで、削除前(左)と削除後(右)の相違を確認できます。 複数のPDFファイルを選択して操作すると、バッチ・モードになります。このモードでは、選択された全てのPDFファイルについて、情報を一括削除します。 |
|
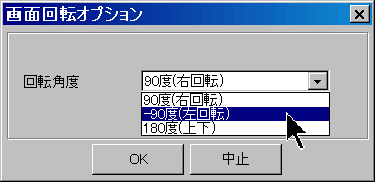 この機能を使うと、グリッドで選択した文書の、ページのセットの画面方向を、右90度、(左)-90度または、180度のいずれかで、倒すことができます。
この機能を使うと、グリッドで選択した文書の、ページのセットの画面方向を、右90度、(左)-90度または、180度のいずれかで、倒すことができます。 |
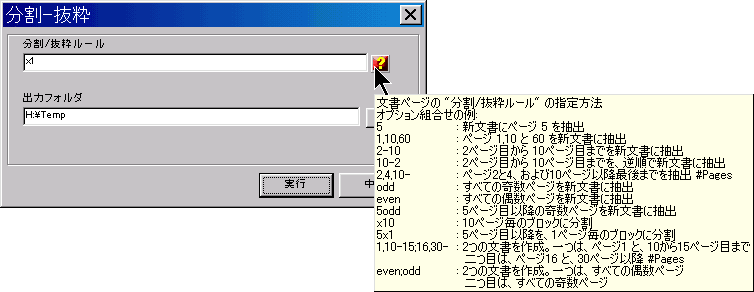
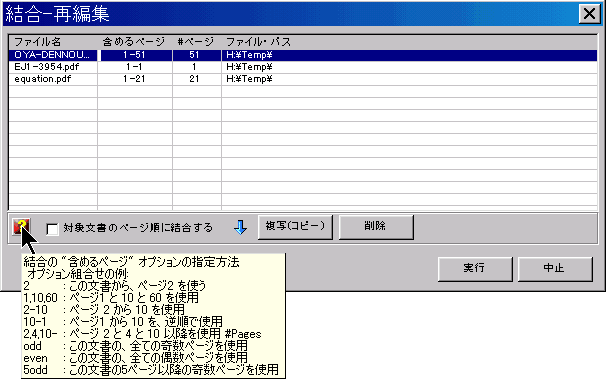
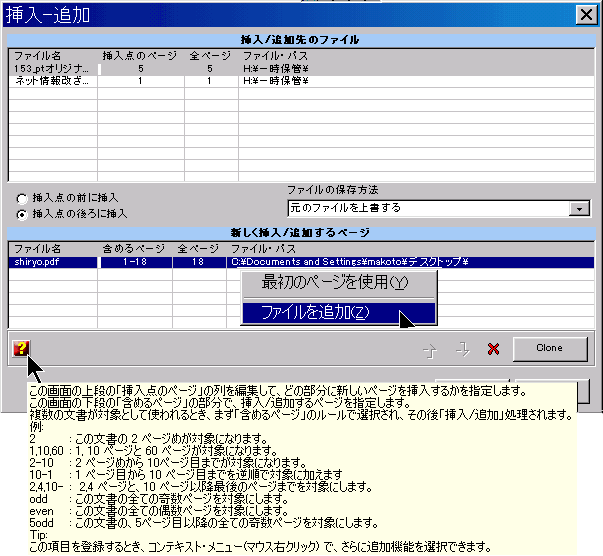
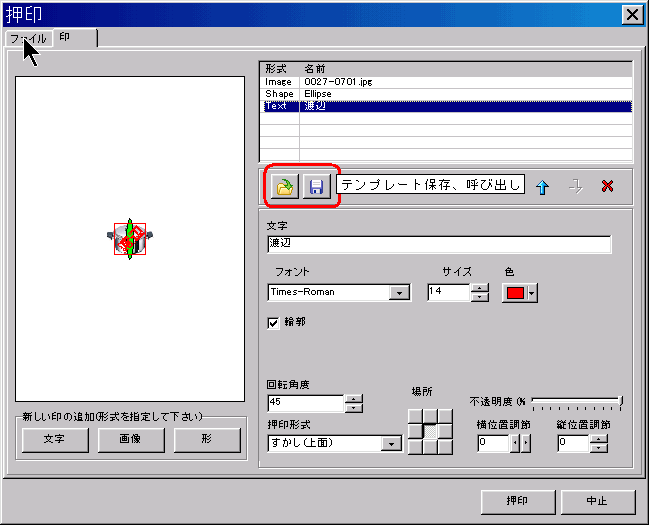
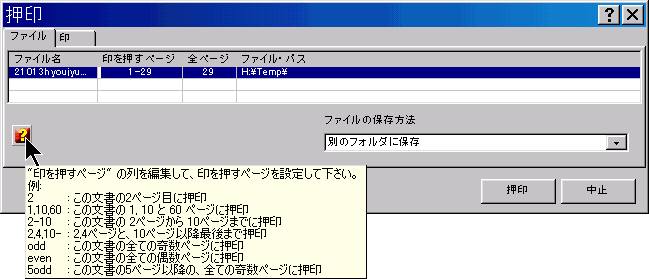
PDFを作成するのに使われる原本を添付したり、PDFの内容を補完する他のファイルを添付するするために、役に立ちます。